Introduction
Coroot is excited to feature an editorial from GlassFlow for our first Open Source Spotlight. We hope to improve the workflow of our global community of SREs and DevOps professionals by sharing exciting projects like Glassflow, which make innovation accessible for everyone through the freedom of open source. If you have an open source or open core project you’d like to see on our blog next, send us a message!
The increasing demand for real-time data analytics is undeniable. Businesses need to make decisions faster than ever, and this requires processing and analyzing data as it arrives. However, building robust, observable real-time data pipelines presents significant challenges. Data engineers often grapple with ensuring data quality, managing complex stream processing logic, and maintaining visibility into the health and performance of the entire system.
ClickHouse is an incredibly powerful open-source analytical database, renowned for its blazing-fast query performance on large datasets. But what about the journey of data into ClickHouse in real-time? How do you efficiently process, deduplicate, and enrich streaming data before it lands in your tables? And critically, how do you keep a vigilant eye on the entire system to quickly diagnose and resolve issues?
This article introduces a completely open-source stack designed to tackle these challenges head-on. We combine the analytical prowess of ClickHouse with GlassFlow, a streaming ETL tool purpose-built for ClickHouse, and Coroot, an eBPF-based observability platform. Our goal is to share our experience in implementing this real-time, observable data stack, detailing the architecture, the specific problems each component solves, and the valuable lessons learned along the way.
Why ClickHouse Alone Isn’t Enough for Our Real-Time Needs
ClickHouse is a phenomenal piece of technology for Online Analytical Processing (OLAP). Its strengths are well-documented and include:
- High-speed analytical queries: It is optimized for complex aggregations and reporting on massive datasets.
- Efficient column-oriented storage: This design reduces I/O and improves data compression, leading to faster query execution.
- Impressive scalability: ClickHouse is designed to scale horizontally and vertically to handle petabytes of data and high query concurrency.
However, when it comes to the intricate demands of real-time streaming ETL (Extract, Transform, Load) directly into ClickHouse, several gaps emerge that necessitate additional tooling:
- Complexities in managing raw data streams: Directly ingesting from sources like Kafka involves managing connections, error handling, and schema evolution, which can be complex without a dedicated intermediary.
- Lack of built-in, sophisticated stream processing: ClickHouse does not natively offer advanced pre-ingestion stream processing capabilities like real-time deduplication or temporal joins before data lands in its tables. While its ReplacingMergeTree engine can handle duplicates post-ingestion, the merging process is asynchronous and uncontrollable, potentially leading to incorrect query results until merges complete. Using the FINAL modifier on queries to obtain accurate, deduplicated data can significantly impact query performance.
- Challenges with exactly-once semantics and late data: Ensuring end-to-end exactly-once processing semantics for the ETL pipeline and efficiently handling late-arriving data at the ETL layer are considerable challenges when relying solely on ClickHouse’s ingestion mechanisms.
- Operational overhead of custom solutions: Building and maintaining custom ingestion scripts to implement these pre-ingestion features imposes a substantial operational burden on engineering teams.
Why We Built & Open-Sourced GlassFlow for ClickHouse Streaming ETL
Recognizing the aforementioned limitations in building sophisticated real-time ingestion pipelines directly with ClickHouse, we identified a clear need for a dedicated tool. This led to the development and open-sourcing of GlassFlow.
The “Why”: Motivation and Goals
Our primary motivations for creating GlassFlow were:
- To simplify and streamline the Kafka-to-ClickHouse data pipeline, making it more accessible and manageable for data engineers.
- To directly address the critical need for pre-ingestion transformations like real-time deduplication and temporal joins natively within the streaming ETL layer. GlassFlow is designed to ensure that data is cleaned and enriched before it reaches ClickHouse, improving data quality at the source.
- To provide a user-friendly, open-source tool that empowers data engineers to build and manage these pipelines efficiently, without proprietary lock-in.
Introducing GlassFlow: Key Features and Benefits for the ClickHouse Ecosystem
GlassFlow is an open-source ETL tool specifically engineered for real-time data processing, focusing on the pathway from Kafka to ClickHouse. It is built to handle common stream processing challenges, such as managing late-arriving events, ensuring exactly-once processing correctness, and scaling effectively with high-throughput data streams.
The table below summarizes GlassFlow’s core features and their advantages:
| Feature | Description | Benefit for ClickHouse Ecosystem |
|---|---|---|
| Real-time Deduplication | Performs duplicate checks on streaming data before writing to ClickHouse, based on a configurable time window (e.g., up to 7 days). | Prevents duplicate records, improving data integrity proactively. |
| Temporal Stream Joins | Joins records from two Kafka streams on-the-fly based on time proximity and a key, enriching events before ingestion. | Allows for contextual data enrichment without complex ClickHouse JOINs. |
| Seamless Kafka Connector | Built-in connector (using NATS-Kafka bridge) simplifies Kafka source setup and automatically extracts data from topics. | Reduces boilerplate and configuration complexity for Kafka sources. |
| Optimized ClickHouse Sink | Efficiently batches data, manages schema, and uses a native ClickHouse connection for good performance. Tunable batch sizes/delays. | Ensures performant and reliable data loading into ClickHouse. |
| Web Interface | Provides a user-friendly UI for designing, managing, and monitoring ETL pipelines. | Simplifies pipeline operations and oversight. |
For instance, the real-time streaming deduplication feature ensures that only unique events (within the configured time window) pass through to ClickHouse, preventing data redundancy. Similarly, temporal stream joins enable enriching an event stream with contextual information from another related stream if their records arrive within a specified time frame, all before the data is persisted.
How GlassFlow Complements ClickHouse
GlassFlow is not a replacement for ClickHouse but rather a specialized tool that enhances its capabilities in a real-time streaming context. It achieves this by offloading complex stream processing tasks (like deduplication and temporal joins) from ClickHouse, allowing ClickHouse to focus on its core strength: analytical querying. By cleaning, transforming, and enriching data upstream before it’s ingested, GlassFlow ensures higher data quality and consistency in ClickHouse tables. Consequently, for certain use cases, it reduces the need for complex post-load transformations within ClickHouse, such as the extensive use of FINAL (which can be slow) or intricate JOIN operations on already landed data, leading to more efficient analytical workloads.
To illustrate how a GlassFlow pipeline might be configured, consider the following JSON snippet. This example defines a pipeline that reads from a Kafka topic named “raw_events,” performs deduplication based on an “event_id” field within a 24-hour window, and then maps and sends the processed data to a ClickHouse table named “processed_events.”
{
"pipeline_id": "kafka-to-clickhouse-dedup-pipeline",
"source": {
"type": "kafka",
"connection_params": {
"brokers": ["kafka-broker:9092"],
"protocol": "SASL_SSL",
"mechanism": "SCRAM-SHA-256",
"username": "user",
"password": "password"
},
"topics": [
{
"name": "raw_events",
"consumer_group_initial_offset": "earliest",
"schema": {
"type": "json",
"fields": [
{ "name": "event_id", "type": "string" },
{ "name": "user_id", "type": "string" },
{ "name": "event_data", "type": "string" },
{ "name": "timestamp", "type": "datetime" }
]
},
"deduplication": {
"enabled": true,
"id_field": "event_id",
"id_field_type": "string",
"time_window": "24h"
}
}
]
},
"sink": {
"type": "clickhouse",
"host": "clickhouse-server",
"port": 9000,
"database": "analytics_db",
"username": "user",
"password": "password",
"table": "processed_events",
"secure": false,
"max_batch_size": 1000,
"max_delay_time": "1m",
"table_mapping": [
{
"source_id": "raw_events",
"field_name": "event_id",
"column_name": "event_id",
"column_type": "String"
},
{
"source_id": "raw_events",
"field_name": "user_id",
"column_name": "user_id",
"column_type": "String"
},
{
"source_id": "raw_events",
"field_name": "event_data",
"column_name": "data",
"column_type": "String"
},
{
"source_id": "raw_events",
"field_name": "timestamp",
"column_name": "event_timestamp",
"column_type": "DateTime"
}
]
}
}
Illustrative GlassFlow pipeline configuration snippet for deduplication or join.
This declarative JSON configuration allows engineers to define complex streaming ETL logic—including source connections, transformations like the deduplication shown, schema mapping, and sink parameters—without writing extensive imperative code. Such a clear definition simplifies pipeline management and versioning. While GlassFlow effectively handles the “T” (Transform) and “L” (Load) aspects of ETL for ClickHouse, the operational health of this entire distributed system still requires dedicated attention, which brings us to the importance of observability.
Why We Added Coroot to the Stack
While GlassFlow addresses the challenges of streaming ETL into ClickHouse, managing a distributed system involving Kafka, GlassFlow, and ClickHouse requires rigorous observability. This is where Coroot enters the picture.
The Need for Deep Insight: Why Observability is Crucial
Operating a modern data pipeline inevitably involves several interconnected components. In such an environment, challenges arise in monitoring the distributed system effectively, quickly diagnosing bottlenecks or performance degradations, and gaining a holistic view beyond basic metrics. Modern systems generate vast amounts of telemetry data (metrics, logs, traces), and the real challenge lies in effectively utilizing this data to gain actionable operational intelligence.
Why Coroot? The Perfect Open-Source Fit
Coroot emerged as an ideal solution for our observability needs for several compelling reasons. It is a powerful open-source APM (Application Performance Monitoring) and observability tool that champions a philosophy of zero-instrumentation observability through the use of eBPF (extended Berkeley Packet Filter). This innovative approach allows Coroot to automatically gather a rich set of telemetry data—including metrics, logs, traces, and even profiles—without requiring manual code instrumentation in the monitored applications. Coroot comes with predefined dashboards and intelligent inspections tailored for modern applications, designed to automatically identify many common issues. It provides the ability to monitor applications, logs, traces, and overall system health within a single, unified platform. Notably, Coroot itself uses ClickHouse as a backend to store the logs, traces, and profiles it collects, leveraging ClickHouse’s performance for its own telemetry data. Its open-source nature and capabilities aligned perfectly with our commitment to building an all-open-source tooling stack.
Coroot in Action: Monitoring Our Real-Time ClickHouse & GlassFlow Pipeline
Integrating Coroot into our stack provides deep insights into the operational aspects of the entire pipeline. We gain crucial visibility into GlassFlow’s processing performance, including metrics like throughput, processing latency, and error rates for each pipeline. Coroot can further provide insights into the Kafka message flow through GlassFlow and the subsequent ClickHouse ingestion performance. It allows for effective monitoring of Kafka consumer lag for GlassFlow’s consumers, ensuring that data processing keeps pace with data arrival. We can closely observe ClickHouse ingestion performance and identify potential backpressure or issues; Coroot can track key Service Level Indicators (SLIs) for ClickHouse clusters, highlighting issues such as failed queries or increased query latency. Coroot’s Service Map feature automatically visualizes the dependencies and interactions across the entire system (Kafka, GlassFlow, ClickHouse), providing a clear overview with no blind spots. We also leverage its SLO (Service Level Objective) tracking capabilities for key pipeline performance indicators.
Our Real-Time ClickHouse Stack: Architecture Deep Dive
The overall architecture combines these specialized components to create a cohesive real-time data platform.
Overview of the End-to-End Architecture
The stack is composed of distinct layers, each fulfilled by a specialized open-source tool:
- Data Sources: Primarily Kafka topics, serving as the entry point for streaming data.
- Stream Processing & ETL: GlassFlow acts as the central engine for consuming, transforming (e.g., deduplicating, joining), and loading data.
- Analytical Data Store: ClickHouse serves as the high-performance analytical database where processed data is stored for querying and analysis.
- Observability Platform: Coroot provides comprehensive monitoring and observability across all components of the pipeline, from Kafka to ClickHouse.
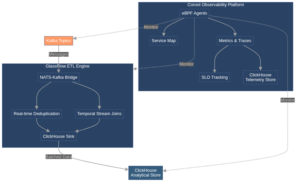
Figure 01: Detailed Architecture Diagram illustrating data flow from
Kafka through GlassFlow to ClickHouse, with Coroot monitoring touchpoints
Component Interactions and Data Flow
The journey of data through this stack begins with messages from Kafka topics being consumed by GlassFlow via its integrated NATS-Kafka bridge. Within GlassFlow, this data undergoes configured processing steps such as deduplication, temporal joins, and other transformations defined in the pipeline. The processed data is then batched and efficiently sunk into target tables in the ClickHouse analytical store by GlassFlow’s ClickHouse sink. Throughout this process, Coroot agents (e.g., coroot-node-agent) collect telemetry using eBPF from Kafka brokers, GlassFlow instances, and ClickHouse servers. Coroot then processes this data and stores it in its own ClickHouse database for analysis and visualization.
Key Technologies Used
The stack relies on these main technologies (versions should ideally be specific, such as “latest stable” or actual version numbers if known and relevant):
- ClickHouse (e.g., latest stable version).
- GlassFlow (e.g., latest stable version). Internally, GlassFlow utilizes a Go backend, NATS for internal messaging and state, and a NATS-Kafka Bridge. The backend application image is glassflow/clickhouse-etl-be:stable.
- Coroot (e.g., latest stable version). Coroot uses eBPF for data collection and ClickHouse for storing its telemetry data.
- Kafka (e.g., a recent stable version).
What we Learnt from Building This Stack
Implementing this integrated stack provided several valuable lessons and reinforced the benefits of this architectural approach.
The Advantages of an All Open-Source Stack
Opting for a completely open-source solution offers compelling advantages. Primarily, it brings cost-effectiveness by eliminating vendor licensing fees and avoiding vendor lock-in, which provides greater long-term flexibility. Furthermore, open-source tools generally offer a high degree of control and customizability over the entire pipeline. The active communities surrounding these projects also provide invaluable support and drive continuous development and improvement.
Observed Benefits
The synergistic combination of these tools resulted in tangible improvements:
- Improved real-time data quality and reliability: GlassFlow’s pre-processing capabilities, particularly real-time deduplication and transformation, ensured that cleaner and more consistent data reached ClickHouse.
- Simplified pipeline development and management: GlassFlow’s user interface and its focused feature set for Kafka-to-ClickHouse ETL streamlined the development and ongoing management of these data pipelines.
- Enhanced operational visibility and faster troubleshooting: Coroot’s comprehensive, low-overhead monitoring across all components provided deep insights into system behavior, enabling quicker diagnosis and resolution of any performance issues or errors.
Challenges Encountered and Solutions
While the benefits were significant, we also navigated some challenges:
- Initial Setup Complexity: Integrating multiple distinct software components, each with its own configuration parameters, can be complex initially. Utilizing containerization technologies like Docker and orchestration tools such as docker-compose (as provided by GlassFlow for its own deployment) significantly simplifies the deployment process and ensures environmental consistency.
- Tuning for Specific Workloads: Optimizing performance requires careful tuning of various parameters, such as GlassFlow’s batch sizes, commit delay times, and deduplication window configurations, as well as ClickHouse’s own settings. This is an iterative process that depends on data volume, velocity, and specific latency requirements. Coroot played a crucial role here by providing the necessary observability to monitor the impact of these tuning adjustments.
- Integrating Monitoring Points: Ensuring that Coroot agents had the necessary permissions (e.g., for eBPF operations) and network visibility to capture telemetry data effectively from all components across the distributed environment required careful attention to deployment configurations and security policies.
Best Practices for Building Similar Systems
From our experience, we recommend the following practices:
- Design for observability from the outset: Do not treat monitoring as an afterthought. Plan how you will monitor each component and their interactions early in the design phase.
- Choose tools that integrate well and solve specific problems effectively: The selected tools; GlassFlow tailored for Kafka-to-ClickHouse ETL, and Coroot designed for low-overhead, broad observability via eBPF are specialized and complement each other’s strengths.
- Leverage community resources for open-source tools: The communities around projects like GlassFlow and Coroot (e.g., Slack channels, GitHub Discussions, forums) are excellent resources for support, best practices, and learning from shared experiences.
The Joint Value of GlassFlow and Coroot
The combination of GlassFlow and Coroot provides a particularly effective solution. GlassFlow ensures that clean, accurately processed, and potentially enriched data reaches ClickHouse, thereby improving analytical accuracy and potentially reducing the query load on ClickHouse by handling transformations upstream. Coroot then ensures the operational health and performance of this entire critical data path—from Kafka, through GlassFlow’s processing stages, to ClickHouse ingestion—providing deep insights with minimal instrumentation overhead.
Final Thoughts
Building a robust, observable, real-time ClickHouse stack is entirely achievable with the right selection and integration of open-source tools. The combination of ClickHouse’s analytical power, GlassFlow’s specialized streaming ETL capabilities for ClickHouse, and Coroot’s low-impact observability provides a potent and effective solution for addressing modern real-time data challenges.
This synergistic trio allows data engineers to focus on delivering value from real-time data, confident in both the quality of the data being ingested into their analytical systems and the health and performance of the pipeline delivering it.
Want to know more?
We also invite you to contribute to or get involved with the GlassFlow community; slack is a great place to start. You can refer to the documentation for more information.

