We’re excited to announce Coroot v1.6, packed with major improvements and new features to make observability even better! Here’s what’s new:
- Multi-tenancy mode
- Coroot Operator for Kubernetes
- High Availability
- OpenShift support
- Significant performance optimizations in Coroot’s agent
- New Coroot Documentation site
Multi-tenancy mode
This feature makes it easier to manage observability for multiple teams, projects, or environments in a single Coroot instance.
With multi-tenancy, each team or project gets its own secure space, so data stays clear and organized. Teams only see what they need, and everything is managed in one place, making operations simpler.
This works by automatically creating separate databases in ClickHouse for each project and labeling metrics in Prometheus to ensure everything remains efficient and secure.
Learn more in the documentation.
Coroot Operator for Kubernetes
Coroot Operator for Kubernetes is designed to simplify the deployment and management of Coroot in Kubernetes clusters.
The Coroot Operator automates the installation, configuration, and upgrades of Coroot, ensuring a seamless and consistent setup across your environments. It eliminates manual work and reduces the risk of errors, making it easier to get started and maintain your observability stack.
It supports the deployment of both Coroot Community and Enterprise editions.
Learn more in the documentation.
High Availability
Coroot now supports high availability by allowing multiple instances to run simultaneously, all connected to the same ClickHouse and Prometheus servers. Each instance maintains its own metric cache, ensuring efficient data retrieval.
By default, Coroot uses SQLite for configuration and incident history. However, for high availability setups, it’s essential to switch to PostgreSQL. This change ensures consistent configuration and incident history across all instances.
To prevent race conditions during SLO compliance checks and deployment tracking, Coroot employs a leader election mechanism using PostgreSQL advisory locks. Only the instance holding the lock performs these tasks. If the leader becomes unavailable, the lock is released, allowing another instance to take over seamlessly.
For detailed setup instructions, refer to the High Availability documentation.
OpenShift support
We’re excited to announce that Coroot now fully supports OpenShift! During our testing, we identified and resolved a few issues to ensure Coroot works seamlessly in OpenShift environments:
- Kernel Tracepoint Changes: Updates in the Red Hat Enterprise Linux kernel broke the tracepoint format, causing issues with the agent. This has been fixed.
- Open vSwitch Network Plugin: OpenShift’s use of zoned conntrack records with Open vSwitch prevented the agent from resolving the actual destinations of TCP connections. We’ve addressed this as well.
With these fixes, we’ve thoroughly validated that all Coroot features run smoothly on OpenShift. This ensures that Coroot has accounted for OpenShift’s unique nuances, providing a seamless experience for users.
Coroot is now ready to empower your OpenShift observability workflows!
Performance optimizations in coroot-node-agent

We’re continually working to make Coroot more efficient, and we’re excited to share recent performance optimizations in coroot-node-agent. These improvements enhance the agent’s ability to handle high-throughput environments while reducing resource consumption.
- Resolving actual TCP connection destinations (after NAT) is now handled directly at the eBPF level. Previously, the agent relied on making requests to the kernel via Netlink, which introduced additional overhead. This change reduces latency and improves performance in high-traffic environments.
- The agent now determines the mount_id for every opened file at the eBPF level. This eliminates the need to resolve a file descriptor’s actual mount on every event, reducing redundant computations and improving overall performance.
- By using a batched perf map reader, the agent now processes multiple events from the kernel at once, significantly reducing CPU consumption in high-throughput environments.
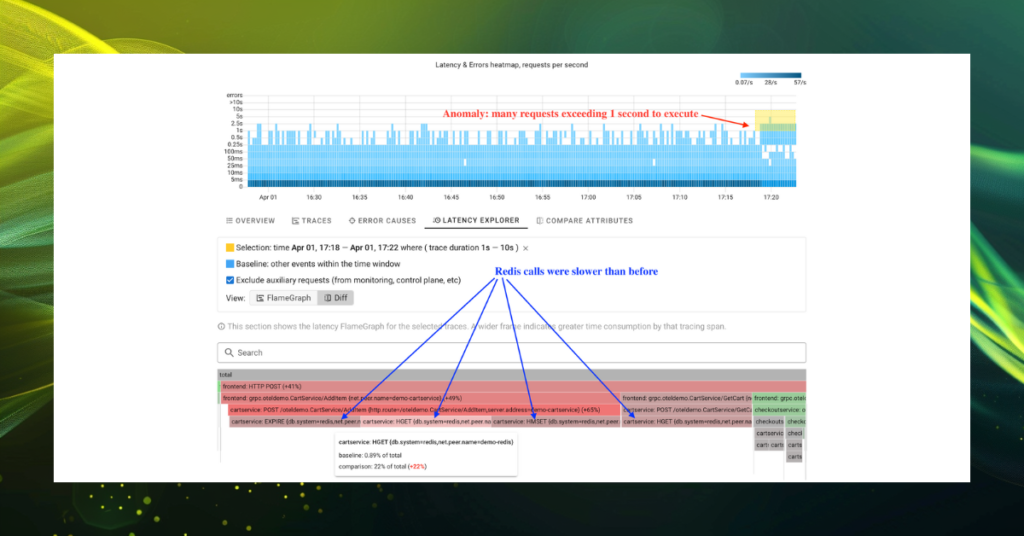
And, of course, we’ve been “dogfooding” with Coroot Continuous Profiling to guide these optimizations. Continuous Profiling made it easy to pinpoint the areas in the code where improvements would have the biggest impact, helping us deliver these performance gains faster and more effectively.
Coroot-node-agent is now faster, more efficient, and ready to handle even the most demanding workloads.
New Coroot Documentation site
We’re excited to share that Coroot Documentation has a new home! It’s now hosted on a dedicated site built with Docusaurus, making it easier to navigate, explore, and improve.
The best part? You can contribute directly to the docs to help make them even better for everyone.
Check it out here: docs.coroot.com!