AI is now a go-to tool for everything from writing to coding. Modern LLMs are so powerful that, with the right prompt and a few adjustments, they can handle tasks almost effortlessly.
At Coroot, we’ve been experimenting with AI for observability. Our goal is to make it useful in the final stage of troubleshooting—when we’ve already identified which service is causing issues, like Postgres, but finding the exact root cause is still tricky due to the many possible scenarios.
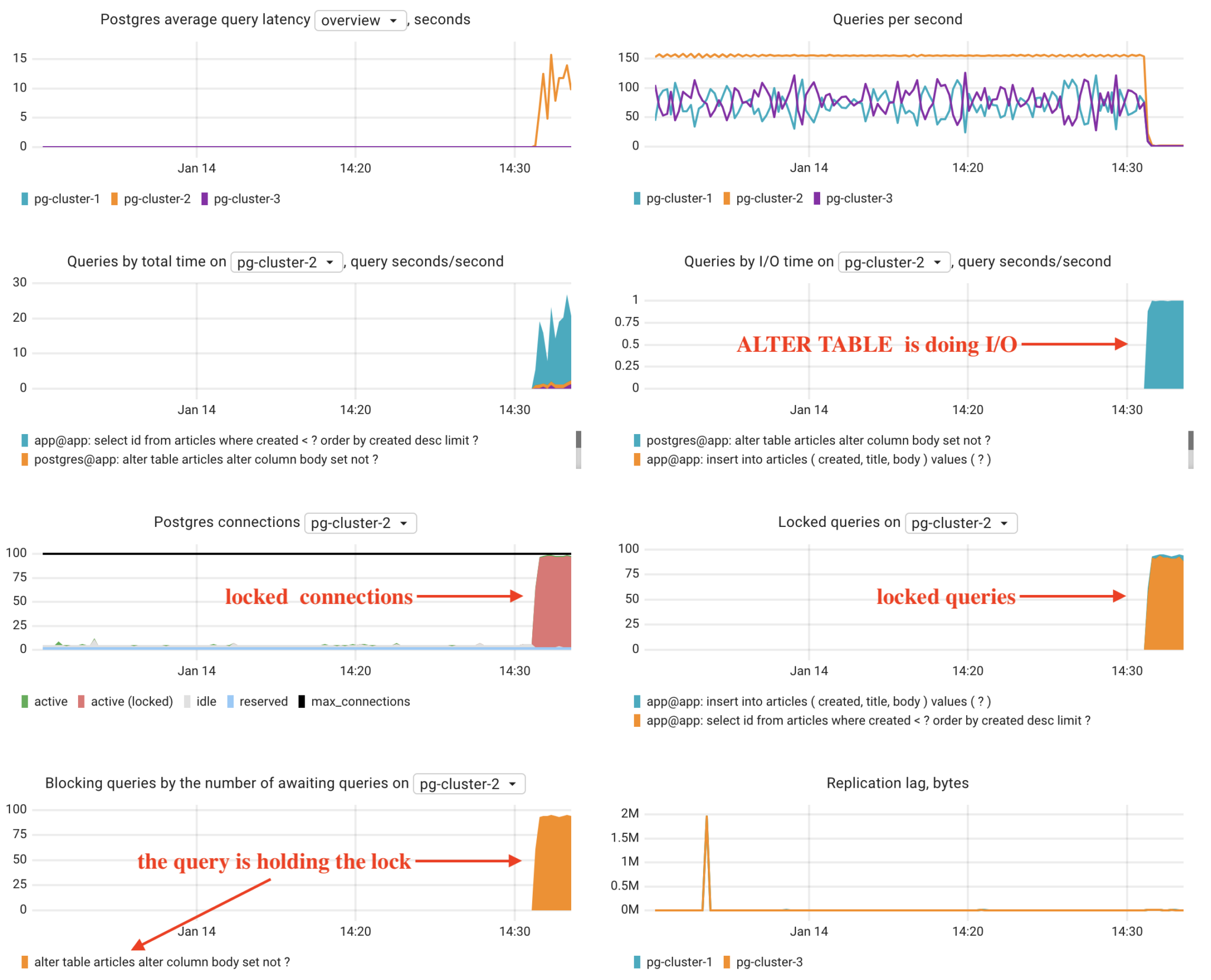
Recently, I was writing a blog post about monitoring a Postgres cluster managed by CloudNativePG. I love using chaos engineering to test our product, so I set up a real Postgres cluster, deployed a client app to generate load, and ran a problematic query:
ALTER TABLE … SET body NOT NULL on a 20GB table.
This query affected performance because it locked the table while checking for null values. Coroot quickly detected the issue and even highlighted the problematic query in its charts.
However, while Coroot provided the data, I still had to explain the charts in my post.
While reviewing the post, my co-founder, Peter Zaitsev, shared this feedback:
“I think this is very good, but it requires too much brainpower and the ability to understand cause and effect in complex systems. The end goal should be for Coroot to provide a specific narrative explanation—just like you did.”
And I completely agree.
Many of our users aren’t experts in areas like databases, network performance, or specific runtimes. We need to provide clear explanations, and ideally, even guidance on how to fix the problem.
So, I decided to test AI again on this specific case. Since laziness often drives progress, I skipped converting my telemetry data into a prompt and instead just uploaded a screenshot as input for the LLMs.
The result shocked me.
OpenAI GPT-4o
Here is my prompt, no other context has been provided:
The answer:From the provided PostgreSQL monitoring dashboard, it appears that an ALTER TABLE statement is causing performance issues, leading to:
Increased Query Latency:
The Postgres average query latency has spiked, especially for pg-cluster-2.
I/O Load from ALTER TABLE:
The ALTER TABLE statement (alter table articles alter column body set not null) is consuming significant I/O, as seen in the Queries by I/O time graph.
Locked Connections and Queries:
The Postgres connections graph shows a sharp rise in locked connections.
The Locked queries graph confirms that queries are blocked due to the ALTER TABLE operation.
The Blocking queries graph indicates that the ALTER TABLE query is holding a lock and blocking multiple other queries.
Replication Lag:
The Replication lag shows a spike, likely due to the ALTER TABLE operation causing a backlog of writes.
Why is this Happening?
ALTER TABLE … SET NOT NULL is a table-wide operation that requires a full table scan to verify that no existing row violates the new constraint.
It locks the entire table and prevents writes/reads from proceeding until the operation completes.
This is especially problematic in a high-load environment where frequent reads/writes occur.
How to Fix This?
Immediate Actions:
Terminate the ALTER TABLE Statement (if possible):
If the system is in production and the lock is causing downtime, consider canceling the query:
SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE query LIKE '%ALTER TABLE articles alter column body set not null%';
2. Restart Blocked Queries:
Once the ALTER TABLE is canceled, the system should return to normal operations. However, some queries might still be waiting, so check for any lingering locks:
SELECT * FROM pg_stat_activity WHERE wait_event IS NOT NULL;
Long-Term Fixes:
Since ALTER TABLE is expensive, consider these best practices:
1. Convert to an Online-Friendly Approach
Instead of ALTER TABLE … SET NOT NULL, use a safer approach:Step 1: Add a check constraint first (non-blocking):
ALTER TABLE articles ADD CONSTRAINT articles_body_not_null CHECK (body IS NOT NULL) NOT VALID;
Step 2: Backfill missing values (if any).
Step 3: Validate the constraint (still non-blocking):
ALTER TABLE articles VALIDATE CONSTRAINT articles_body_not_null;
Step 4: If no violations exist, alter the column:
ALTER TABLE articles ALTER COLUMN body SET NOT NULL;
2. Use pg_repack for Zero-Downtime Migrations
pg_repack allows reorganizing tables without full locks
pg_repack -t articles --dbname=mydatabase
3. Perform Schema Changes During Low-Traffic Periods
If running in production, execute schema changes during maintenance windows to reduce impact.
4. Partition Large Tables
For frequently altered large tables, consider partitioning to isolate operations on smaller segments.
Conclusion
The ALTER TABLE operation is locking the articles table, causing significant query delays and replication lag. The best approach is to:
Cancel the operation if causing downtime.
Use an online-safe alternative (check constraint + validation).
Schedule schema changes carefully.
Use tools like pg_repack for minimal impact.
That’s super impressive and surprisingly accurate. What shocked me the most was the model’s ability to interpret the screenshot as input.
We’re integrating AI into Coroot but won’t use screenshots, as it’s much simpler to explain complex system parameters programmatically.
It’s exciting that an LLM can ‘understand’ our domain and generate deep summaries with actionable insights. However, relying on a single vendor didn’t seem like a robust solution.
Fortunately, DeepSeek has emerged as a strong alternative to OpenAI’s model, especially with the recent release of its R1 model. Its open-source nature also gives us the option to self-host if needed, though that is not in our plans for now.
Now, let’s repeat the experiment using DeepSeek-R1:
DeepSeeek-R1
The answer:
The data indicates a significant performance issue in pg-cluster-2, primarily caused by a long-running ALTER TABLE command on the articles table. This operation is causing table locks, blocking other critical queries (e.g., SELECT and INSERT), leading to:
– High query latency (10-15 seconds).
– A surge in active/locked connections.
– Query throughput drops.
– Replication lag in other clusters (minor).
Root Cause
The ALTER TABLE statement (alter table articles alter column body set not ?) is:
Creating a chain of waiting queries, increasing latency and connection usage.
Solutions
Immediate Fixes
Terminate the ALTER TABLE command (if safe):
-- Find the PID of the ALTER TABLE query SELECT pid, query FROM pg_stat_activity WHERE query LIKE '%alter column body%'; -- Terminate it SELECT pg_terminate_backend(<PID>);
Caution: Ensure this won’t corrupt data (e.g., if the ALTER is part of a migration).
Reschedule the DDL Operation:
Run schema changes during low-traffic periods or use online DDL tools like:
– pg_repack (to rebuild tables without locks).
– CREATE INDEX CONCURRENTLY (for index-related changes).
Optimize the ALTER TABLE:
If the column is being set to NOT NULL, ensure it already contains no NULL values. Pre-run:
UPDATE articles SET body = '' WHERE body IS NULL; -- Example cleanup
Long-Term Improvements
Use Lock Timeouts:
Add a lock timeout to prevent indefinite blocking:
SET LOCAL lock_timeout = '5s'; ALTER TABLE ...;
Monitor and Tune Queries:
– Optimize the `SELECT id FROM articles WHERE created < ? …` query with an index on created.
– Batch the INSERT operations to reduce contention.
Connection Pooling:
Use a connection pooler (e.g., PgBouncer) to manage active connections and prevent exhaustion.
Replication Checks:
Investigate replication lag in `pg-cluster-1` and `pg-cluster-3` to ensure failover readiness.
Summary
The blocking ALTER TABLE is the critical issue. Address it first by terminating or rescheduling the operation, then implement safeguards to avoid similar incidents. Optimize queries and use non-locking DDL tools for future schema changes.
DeepSeek-R1 delivers an answer that is quite close to OpenAI’s. I’d say it is accurate enough to be a viable alternative to OpenAI’s models.
Additionally, I tested other open-source models in my lab, but I was only able to run LLMs with up to 70 billion parameters. In this range, I didn’t find anything that came close to OpenAI or the larger DeepSeek models for our needs.
Does this mean AIOps is finally here?
Yes, but only if you have enough data describing your system’s behavior.
As you saw on Coroot’s dashboard, the answer was already there, we just needed to interpret the charts and make a conclusion. The real magic of AI in this case was its ability to understand the bigger picture, apply domain knowledge, and suggest how to fix the issue. This wouldn’t have been possible with just CPU, memory, and disk usage alone.
That’s where Coroot comes in. It covers the full observability cycle, from collecting telemetry data to providing actionable insights, helping you pinpoint root causes in seconds. AI-powered features are on the way.