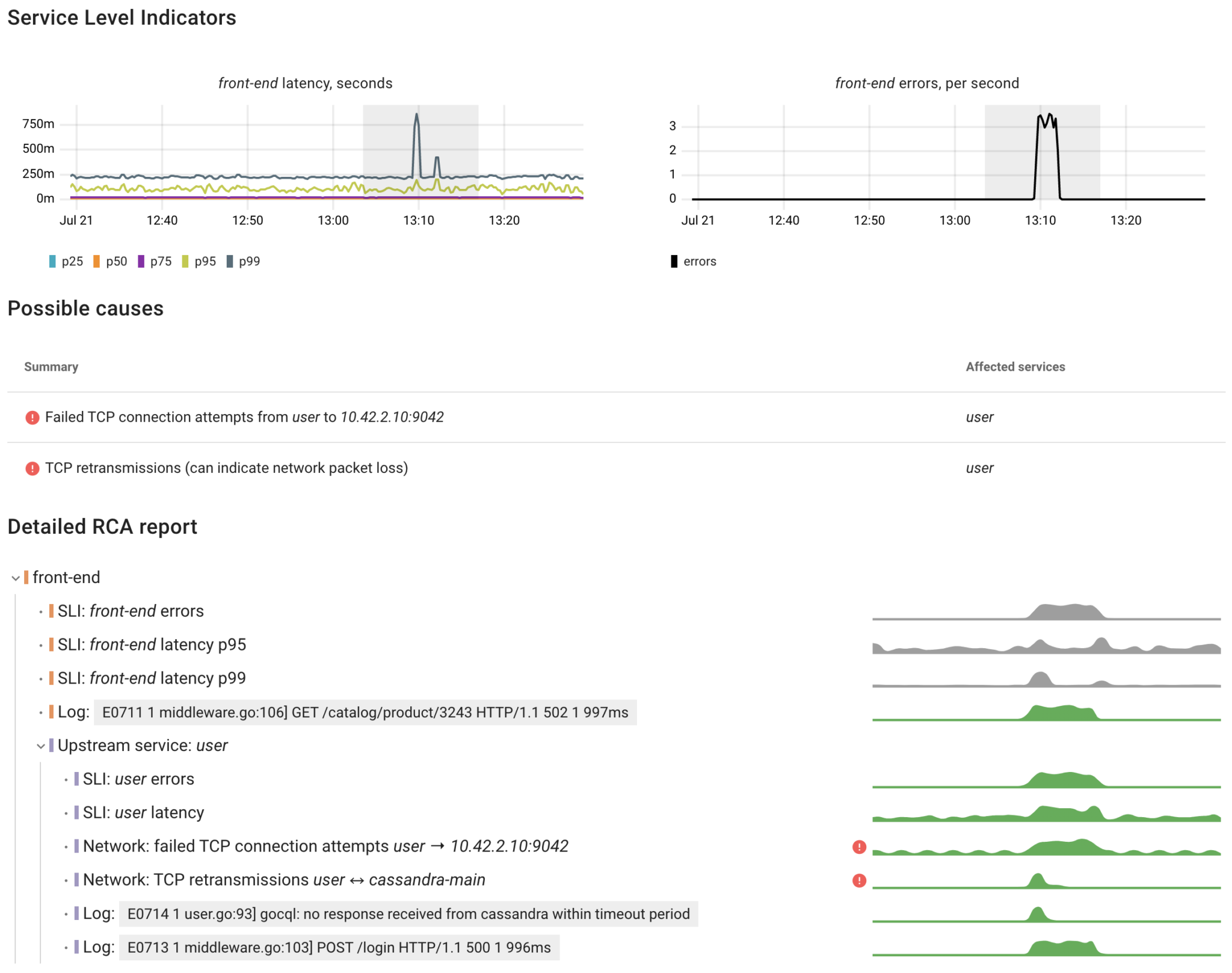
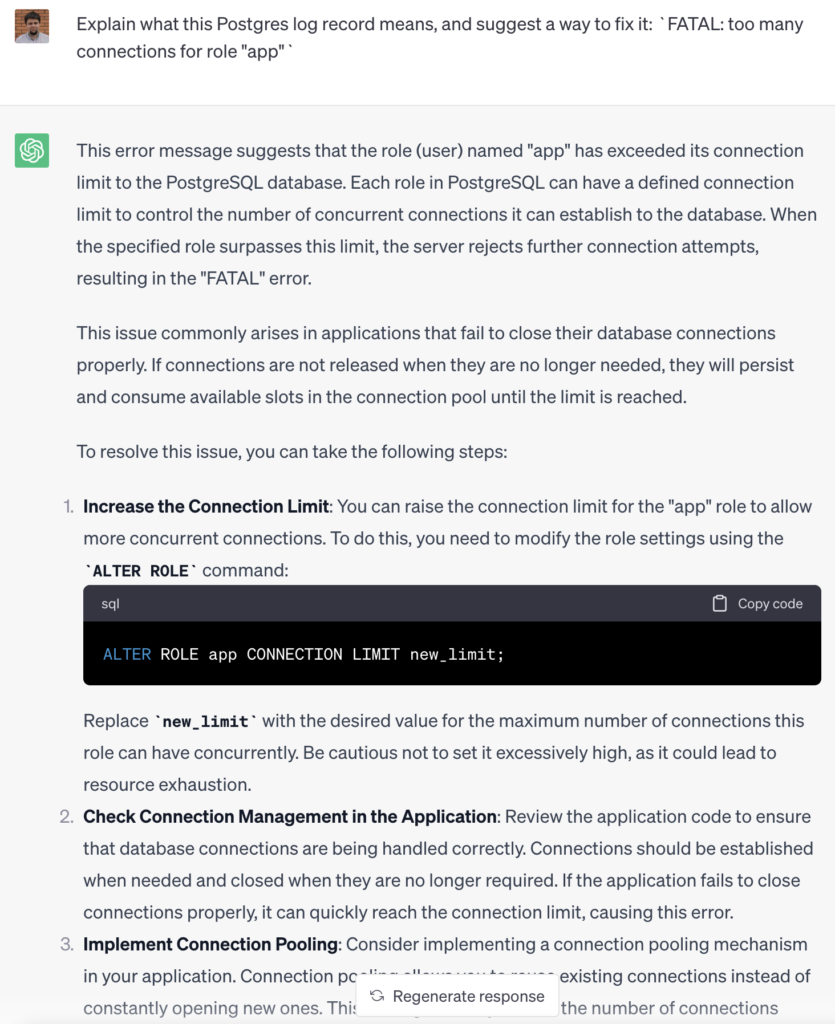
In a manual troubleshooting process, the typical approach involves investigating a set of hypotheses using metrics, logs, and traces. For example, when trying to determine why a service is responding slower than usual, several potential issues should be considered. These may include resource-related problems, such as CPU starvation and I/O bottlenecks. Additionally, factors like latency and availability of dependent services and databases, as well as network issues, should be taken into account during the investigation.
For instance, let’s attempt to confirm or disprove the hypothesis that the service is responding slower than usual due to a lack of CPU time.
Well, let’s see what CPU-related container metrics cAdvisor (the most popular container metrics exporter for Prometheus) exposes:
- container_cpu_system_seconds_total – cumulative system cpu time consumed
- container_cpu_usage_seconds_total – cumulative cpu time consumed
- container_cpu_user_seconds_total – cumulative user cpu time consumed
- container_cpu_cfs_periods_total – number of elapsed enforcement period intervals (for enforcing CPU limits)
- container_cpu_cfs_throttled_periods_total – number of throttled period intervals
- container_cpu_cfs_throttled_seconds_total – total time duration the container has been throttled
Unfortunately, none of these metrics can help us answer the question. In a scenario where our container has no CPU limit and another application consumes all available CPU time on the node, the mentioned metrics will only show a collateral decrease in the container’s CPU consumption.
Perhaps an anomaly detection algorithm could recognize some anomaly in these metrics. However, it falls short in helping us understand what’s going on because these metrics simply don’t reflect the processes occurring in the system.
Now, let’s find a more telling metric for this scenario.
Only a few people know that the Linux kernel has a built-in capability to track the precise amount of time each process spends waiting for a CPU. If this metric shows a CPU delay of 500ms per second for a given container, it means that the container’s performance is slowed down by 500ms every second due insufficient CPU time.
If we determine that the cause is indeed a lack of CPU time, we can then proceed to investigate the underlying reasons for this behavior. Possible factors to consider include a noisy neighbor, insufficient CPU capacity, or CPU throttling.
On the contrary, if there is no CPU delay, it ensures that this particular container is not facing a shortage of CPU time, even if the CPUs on the node are utilized at 100%.
At Coroot, we dedicate significant effort into developing agents that gather these sorts of meaningful metrics. Thanks to eBPF, we can now gather any desired metrics directly from the Linux kernel without requiring our users to instrument their code.
It should be noted that having such metrics is necessary but not sufficient to build an AI-based root cause analysis engine.