
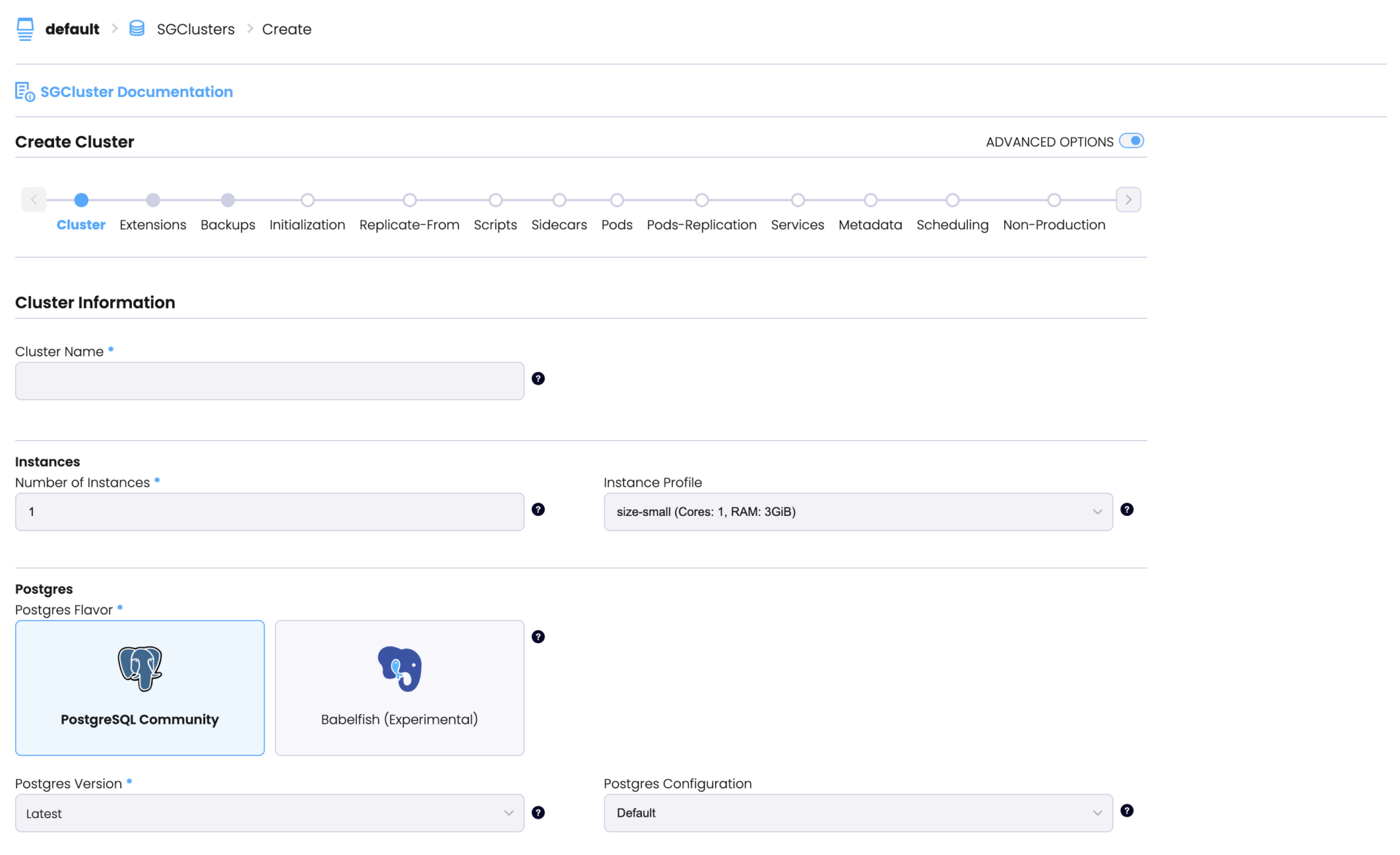
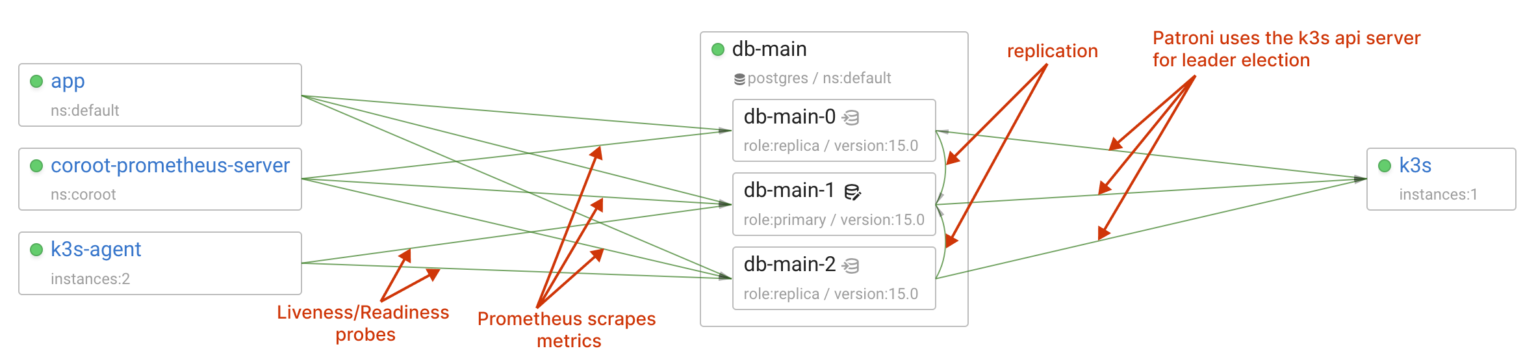
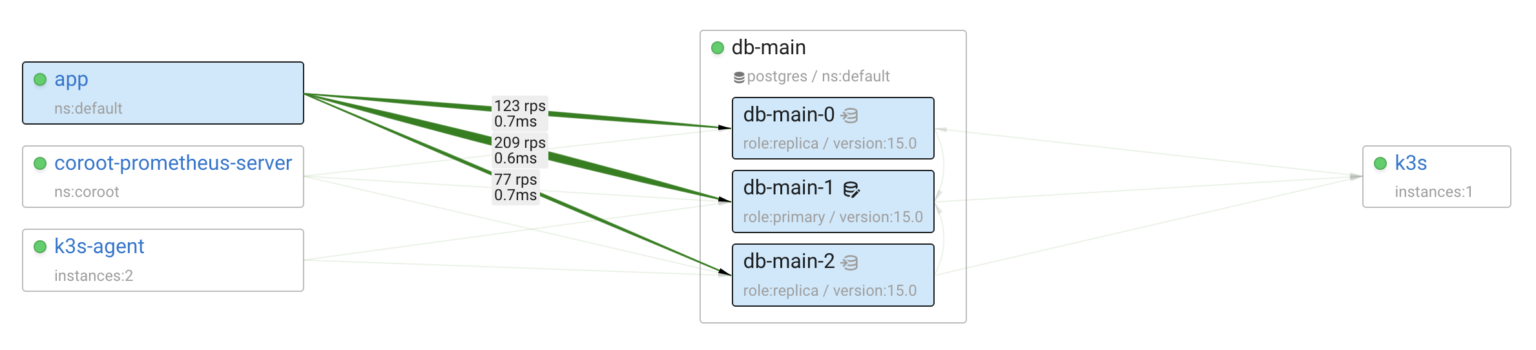

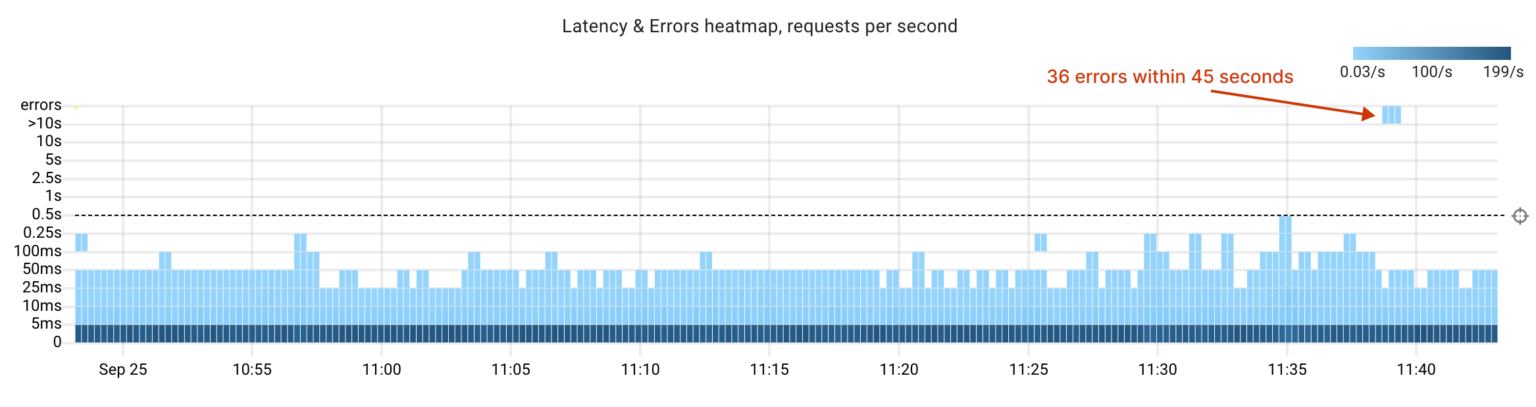
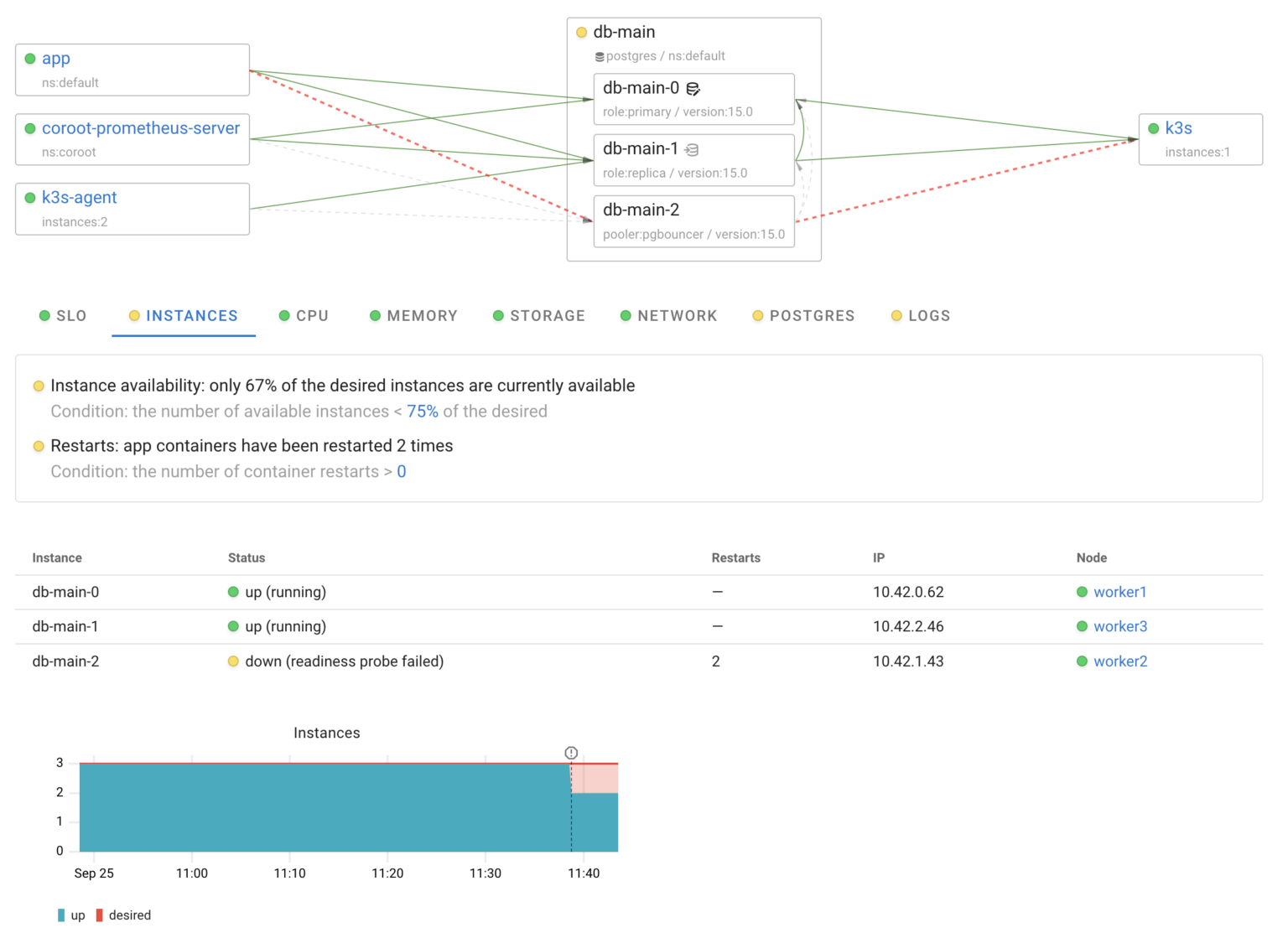

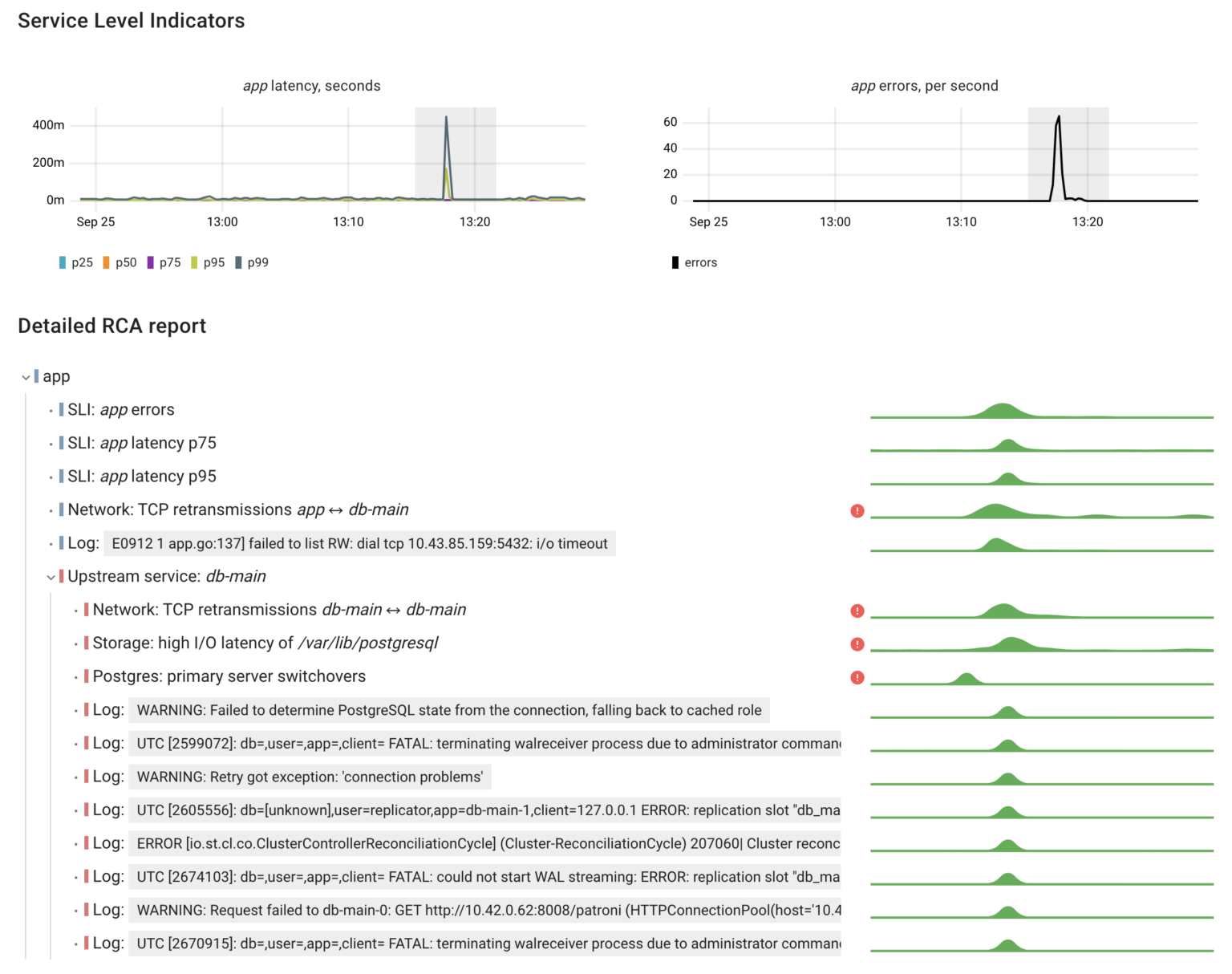
After our experiments, we can confidently say that StackGres and its underlying components effectively handle failures in the cluster.
As for my experience with StackGres, it was pleasantly surprising. What I liked most was its user interface and how the operator enables you to schedule and monitor Database Operations, including minor/major upgrades, vacuuming, and repacking.
When it comes to monitoring, it’s great that StackGres offers built-in Postgres monitoring capabilities. However, in shared infrastructures like Kubernetes, it’s essential to have a broader view — seeing all the applications, understanding their interactions, and monitoring shared compute resource usage.
Coroot can help you achieve this by providing comprehensive observability across the entire cluster. StackGres is supported out-of-the-box in both Coroot Cloud and Coroot Community Edition.
Try Coroot Cloud now (14-day free trial is available) or follow the instructions on our Getting started page to install Coroot Community Edition.
If you like Coroot, give us a ⭐ on GitHub️.
Any questions or feedback? Reach out to us on Slack.


